A Sharded PIR Design
for the Ethereum State
A practical path to private reads of Ethereum data

Ethereum users routinely query state data from remote servers The content and the patterns of these queries leak privacy
a curious/malicious server can profile a user just by tracking what they read — undermining other privacy measures the user has worked hard to follow (eg shielding assets).
The edge reads, providers see 👀
they don't or can't hold the full state, so they query remote providers
A read is a fingerprint
- Holdings inferred from which balances and slots you poll
- On-chain ↔ off-chain identity correlated by IP, timing, query mix
- Frontrunning & MEV: a wallet polling a liquidation price is a tell
- Behavioral profile assembled over time, even without any tx broadcast
What does “the edge” actually read?
eth_getBalance(@blockN)eth_getStorageAt(@blockN)archival state
(“data warehouse” in traditional db lingo)
Answer: a bit of everything — any complete privacy story has to cover all three.
The Ethereum state
The Ethereum state, briefly
- A key→value store of accounts; code and storage live one indirection deeper
- Committed under the state root (a Merkle-Patricia trie) in every block header
- Every read is verifiable with Merkle roots to the state root in the block header
Reading a value can entail fetching a merkle proof anchored to the state root in the block header — if the user wants to independently verify the value (and soon, the zkVM proof of that header).
MPT will be upgraded from, eventually
MPT — today arity 16
- Heavy proofs — 15 siblings × 32 B per level
typical ~2.4–2.9 KB (depth 5–6) · worst-case ~3.8 KB (depth ~8)
- Worst-case stateless proof per block ~300 MB
- Storage slots require a second trie traversal
- Keccak — slow in zkVMs
UBT — EIP-7864 (draft) arity 2
- Lean proofs — 1 sibling × 32 B per level → ~1 KB (~4× smaller)
- Single trie — storage & code under one root
- Snark-friendly hash (BLAKE3 / Poseidon — exact choice TBD) → 3–100× proving speedup
- Page-based locality — meaningful gas savings under Verkle/UBT witness pricing for storage-heavy dApps
We are using UBT as the source DB for PIR, with a zk proof of its equivalence to mainnet MPT.
Many roots today, one tomorrow
- One state root + many storage roots + a flat code store. Three commitment regimes side by side.
- A balance proof = path through state trie. A storage-slot proof = two paths.
- One root, one keyspace. Account, code chunks, storage slots all addressed by stem.
- For PIR: one universal interface, one slicing schema.
Private Information Retrieval (PIR)
PIR at a glance
Private Information Retrieval: read $\mathrm{DB}[x]$ without revealing $x$.
- Server holds $\mathrm{DB}$; client wants $\mathrm{DB}[x]$
- Client sends a query $q$ that encodes the index of $x$ under a cryptographic veil
- Server computes a response $r$ — learning nothing about $x$
- Client decodes $r$ to get $\mathrm{DB}[x]$
A one-hot vector picks one row
- A vector $q$ of length $N$
- Zero everywhere except a single $1$ at index $x$
- Inner-product against any vector $\mathrm{DB}$ —
- … selects exactly $\mathrm{DB}[x]$, zeroing the rest.
We can send $q$ to the server while hiding the “$1$”
Single-server PIR: encrypt the one-hot
- Client encrypts each entry of $q$ under SHE/FHE.
- Server computes $\sum_i q[i] \cdot \mathrm{DB}[i]$ homomorphically — an inner product on ciphertexts.
- Client decrypts the response and recovers $\mathrm{DB}[x]$.
Privacy here is computational — it relies on the semantic security of the encryption.
The catch: the server must touch every record to compute that sum — cost is $O(N)$ per query. Skipping any record would leak that the client didn’t want it.
Two non-colluding servers
PIR with XOR’ing
- Client wants index $x$; encodes it as a one-hot vector $q$ over $[N]$.
- Splits $q$ into two random XOR shares: $q = q_1 \oplus q_2$. Each share alone is uniform random.
- Sends $q_1$ to $S_1$, $q_2$ to $S_2$. Each server XORs the $\mathrm{DB}$ entries selected by its share.
- Client XORs the responses: $r_1 \oplus r_2 = \mathrm{DB}[x]$.
Privacy here is information-theoretic — it follows from how the query is split, not from any encryption.
Currently we are focused exclusively on single-server schemes
The Performance Tradeoffs of PIR Schemes
The design space

No single PIR scheme dominates
| family / examples | online server cost | client storage | per-client server state | update cost / freshness | online comm |
|---|---|---|---|---|---|
| Server-stateful Spiral · VIA-C · OnionPIRv2 | ! | ✓ | × | ✓ | ✓ |
| Double-stateless YPIR · VIA · InsPIRe | ! | ✓ | ✓ | ✓ | ✓ |
| Download-hint SimplePIR · DoublePIR | ! | ! | ✓ | × | ✓ |
| Interactive-hint RMS24 · Plinko · HarmonyPIR | ✓ | ! | ! | ! | ✓ |
Sharding
Sharding the Ethereum State
Sharding the Ethereum State
Knowing which slice → leakage
which slice is being queried leaks privacy — the server knows the content of each slice, and can make correlations over time
Genuine + decoy queries = full privacy
What the client knows vs. what the network observer sees.
Client’s view — ground truth
Observer’s view — on the wire
Observer’s view = monolithic PIR over the whole state. Performance = per-slice optimized.
The wire is safe, but what about the clock
Decoys hide which slice — per-slice response times can give it away.
The failure mode
- Response time is different across PIR engines.
- If the client acts as soon as it receives the response of the real query, the observer correlates time → recovers which slice.
Mitigations
- Wait-for-all: client doesn’t act until every shard has responded.
- $m$-of-$k$: tolerate slowest few; discard their slices this round.
- Constant background traffic: client always queries every slice.
Middleware
A universal PIR interface
The edge keeps speaking standard Ethereum RPC. The PIR backend evolves independently.
- Edge unchanged. Wallets, dApps, light clients keep speaking
eth_getBalance,eth_getProof, … - Adapter in the SDK (ethers/viem) translates RPC into a GraphQL-shaped PIR query plan.
- Query router constructs k queries (1 real + decoys), dispatches per-slice.
- Decoupling: PIR families and slice boundaries evolve under the interface.
Summary of Sharded Design
Optimizations
Three levers to scale sharded PIR
Shrink the DB
Reduce what each PIR engine has to scan per query.
- → PIR for Merkle proofs — serve proofs, not nodes
- → SNARKify archival roots — serve proofs of stem nodes instead of Merkle proofs
Slice smarter
Carve slices along their natural seams — especially mutability.
- → Sidecar pattern — isolate the mutable tail
- → Verifiable UBT equivalence — capitalize on the uniformity of binary tries
Build better schemes
Push the per-slice scheme harder — especially toward GPU-native designs.
- → Double-stateless GPU-tailored R&D
- → Delegated hints · DEPIR to the rescue?
Snarkifying away merkle roots → reduce db size massively
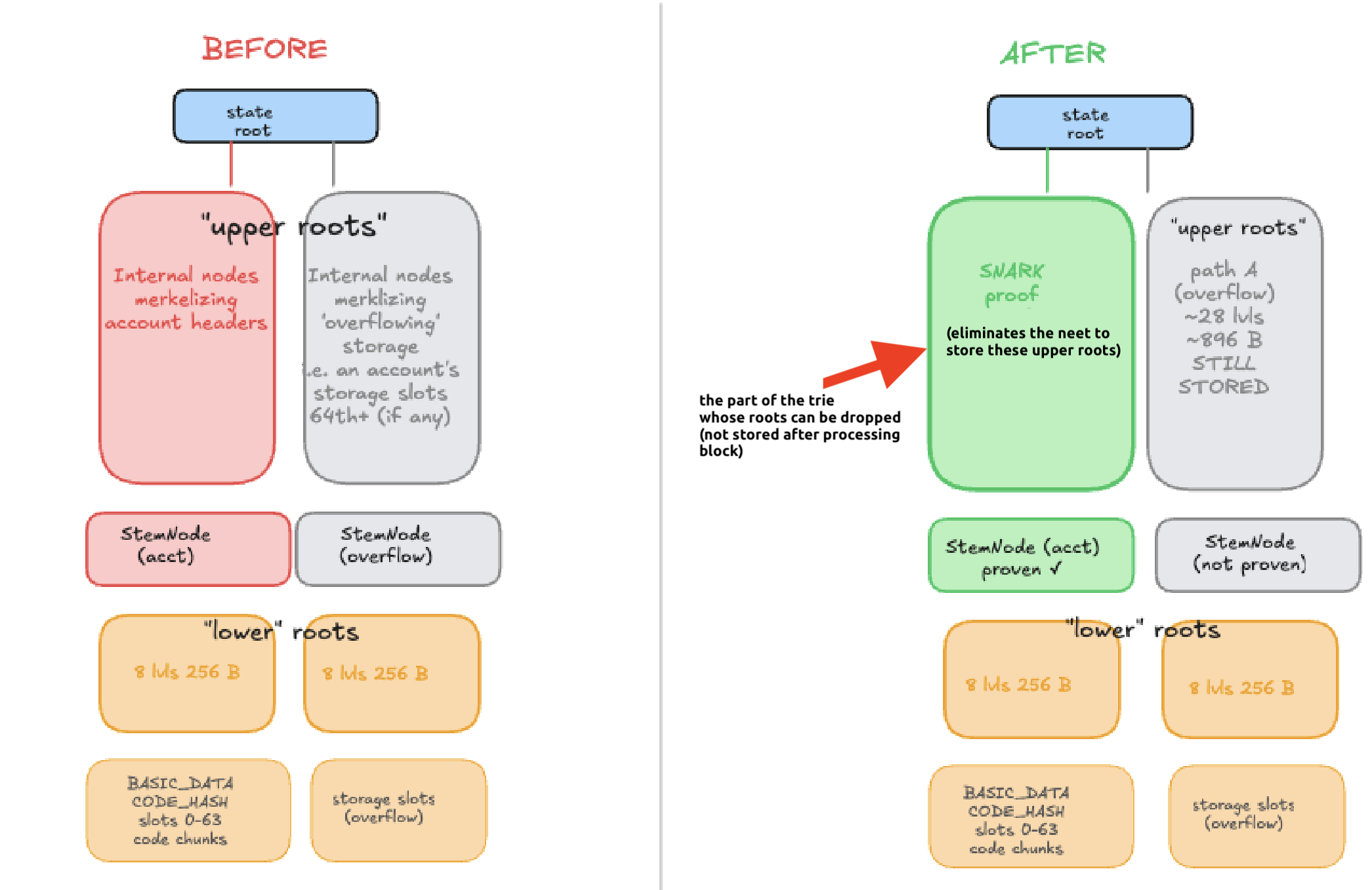
What gets dropped: upper trie levels — most-mutated, biggest by volume. Lower nodes & leaves stay; PIR continues unchanged.
Why it pays: ~50–80% archival DB-size reduction (§8 of the ethresear.ch post). Smaller DB → cheaper PIR per query.
Isolate mutability — the sidecar pattern
Big snapshot stays cold; fresh writes live in a small, fast engine; client always sees the freshest answer.
Verifiable UBT ↔ MPT equivalence
∀ (key, value): (key, value) ∈ MPT ⇔ (key, value) ∈ UBT
Why this anchors everything
- PIR backend can use UBT before it lands on mainnet.
- SNARKification (slide 30) operates on the UBT side.
- One verification surface for all PIR engines — the UBT root.
Cost shape
- One proof per block, generated server-side; clients verify it once.
- SNARK-friendly UBT hash (BLAKE3 / Poseidon—TBD) keeps prover work tractable.
Researching double-stateless GPU schemes
Active in-house research direction: PIR schemes where both client and server are stateless — and the server kernel is shaped to be GPU-native from the start.
Why double-stateless?
- ✓ No per-client server state — server scales horizontally without client tracking.
- ✓ No client hint to keep fresh — client carries only its keys.
- ✓ Clean trust model — every client looks the same to the server.
- ✓ Updates are clean — no broadcast hint to invalidate, no per-client preproc to redo.
Family includes e.g. HintlessPIR, YPIR, VIA, InsPIRe. Online server work is still $O(N)$ — but with much smaller constants than FHE-PIR.
Why GPU-tailored?
- ▸ Server work is dense linear algebra — matrix–vector multiply over the DB.
- ▸ Batch friendly — many concurrent queries amortize one DB pass.
- ▸ Small modular params fit in GPU L2 cache — bandwidth-bound, not compute-bound.
- ▸ Stateless server means many GPUs can serve the same DB without coordination.
Designing the scheme around the GPU memory hierarchy — not just porting an existing scheme to CUDA — is what unlocks order-of-magnitude gains. (See Part 4 for current GPU PIR numbers.)
Progress, ongoing work, references
Progress
- Correctness-focused specs of Plinko, RMS24, VIA schemes.
- Speccing Plinko surfaced the invertible PRF as an intractable bottleneck before months of impl work.
- GPU acceleration of insPIRe scheme.
- Reproducing benchmarks of existing schemes.
Ongoing work
- New double-stateless GPU-tailored schemes — can they hit GPIR throughput while keeping the cleaner trust model?
- Universal PIR middleware spec & wallet integration.
- SNARKification cost analysis (binary trie).
References
- Sharded PIR design — the ethresear.ch post.
- GPIR (latest) — SOTA GPU acceleration of PIR.
- PIR-Eng-Notes — per-scheme papers, specs, engineering notes.
- PIR benchmarks & PIR specs on Private Reads.



